DevOps(9)--GitLabPipeline语法
GitLabPipeline语法
1. 参数列表
2. job
在每个项目中,我们使用名为.gitlab-ci.yml的YAML文件配置GitLab CI / CD 管道。
这里在pipeline中定义了两个作业,每个作业运行不同的命令。命令可以是shell或脚本。
job1:
script: "execute-script-for-job1"
job2:
script: "execute-script-for-job2"
可以定义一个或多个作业(job)。
每个作业必须具有唯一的名称(不能使用关键字)。
每个作业是独立执行的。
每个作业至少要包含一个script。
3. script
job:
script:
- uname -a
- bundle exec rspec
注意:有时, script命令将需要用单引号或双引号引起来. 例如,包含冒号命令( : )需要加引号,以便被包裹的YAML解析器知道来解释整个事情作为一个字符串,而不是一个"键:值"对。
使用特殊字符时要小心: : , { , } , [ , ] , , , & , * , # , ? , | , - , < , > , = ! , % , @ .
4. before_script
用于定义一个命令,该命令在每个作业之前运行。必须是一个数组。指定的script与主脚本中指定的任何脚本串联在一起,并在单个shell中一起执行。
5. after_script
用于定义将在每个作业(包括失败的作业)之后运行的命令。这必须是一个数组。指定的脚本在新的shell中执行,与任何before_script或script脚本分开。
可以在全局定义,也可以在job中定义。在job中定义会覆盖全局。
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
stages:
- build
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "mvn clean "
- echo "mvn install"
after_script:
- echo "after script in job"
deploy:
stage: deploy
script:
- echo "hello deploy"
after_script:
- echo "after-script"
after_script失败不会影响作业失败。
before_script失败导致整个作业失败,其他作业将不再执行。作业失败不会影响after_script运行。
6. stages
用于定义作业可以使用的阶段,并且是全局定义的。同一阶段的作业并行运行,不同阶段按顺序执行。
stages:
- build
- test
- deploy
这里定义了三个阶段,首先build阶段并行运行,然后test阶段并行运行,最后deploy阶段并行运行。deploy阶段运行成功后将提交状态标记为passed状态。如果任何一个阶段运行失败,最后提交状态为failed。
6.1 排序
一个标准的yaml文件中是需要定义stages,可以帮助我们对每个stage进行排序。
stages:
- build
- test
- codescan
- deploy
6.2 .pre & .post
.pre始终是整个管道的第一个运行阶段,.post始终是整个管道的最后一个运行阶段。 用户定义的阶段都在两者之间运行。.pre和.post的顺序无法更改。如果管道仅包含.pre或.post阶段的作业,则不会创建管道。
在stages即使未定义.pre & .post,在job中也可以使用。
stages:
- build
- test
- deploy
codescan:
stage: .pre
script:
- echo "codescan"
7. stage
是按JOB定义的,并且依赖于全局定义的stages 。 它允许将作业分为不同的阶段,并且同一stage作业可以并行执行
unittest:
stage: test
script:
- echo "run test"
interfacetest:
stage: test
script:
- echo "run test"
可能遇到的问题: 阶段并没有并行运行。需要将runner每次运行的作业数量更改一下,默认是1。
concurrent = 10
8. variables
定义变量,pipeline变量、job变量、Runner变量。job变量优先级最大。
9. 实例1
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
stages:
- build
- test
- codescan
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "mvn clean "
- echo "mvn install"
- echo "$DOMAIN"
after_script:
- echo "after script in buildjob"
unittest:
stage: test
script:
- echo "run test"
deploy:
stage: deploy
script:
- echo "hello deploy"
- sleep 2;
codescan:
stage: codescan
script:
- echo "codescan"
- sleep 5;
after_script:
- echo "after-script"
- ech
上述我们没有选择tags,所以需要在runner的配置改一下,让其可以运行没有tag的pipeline。
10. tags
用于从允许运行该项目的所有Runner列表中选择特定的Runner,在Runner注册期间,您可以指定Runner的标签。
tags可让您使用指定了标签的runner来运行作业,此runner具有ruby和postgres标签。
job:
tags:
- ruby
- postgres
给定带有osx标签的OS X Runner和带有windows标签的Windows Runner,以下作业将在各自的平台上运行。
windows job:
stage:
- build
tags:
- windows
script:
- echo Hello, %USERNAME%!
osx job:
stage:
- build
tags:
- osx
script:
- echo "Hello, $USER!"
11. allow_failure
allow_failure允许作业失败,默认值为false 。启用后,如果作业失败,该作业将在用户界面中显示橙色警告. 但是,管道的逻辑流程将认为作业成功/通过,并且不会被阻塞。 假设所有其他作业均成功,则该作业的阶段及其管道将显示相同的橙色警告。但是,关联的提交将被标记为"通过”,而不会发出警告。
job1:
stage: test
script:
- execute_script_that_will_fail
allow_failure: true
12. when
on_success前面阶段中的所有作业都成功(或由于标记为allow_failure而被视为成功)时才执行作业。 这是默认值。
on_failure当前面阶段出现失败则执行。
always -执行作业,而不管先前阶段的作业状态如何,放到最后执行。总是执行。
12.1 manual 手动
manual -手动执行作业,不会自动执行,需要由用户显式启动. 手动操作的示例用法是部署到生产环境. 可以从管道,作业,环境和部署视图开始手动操作。
比如在deploy阶段添加manual,则流水线运行到deploy阶段为锁定状态,需要手动点击按钮才能运行deploy阶段。
12.2 delayed 延迟
delayed 延迟一定时间后执行作业
有效值'5',10 seconds,30 minutes, 1 day, 1 week 。
13. 案例2
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
stages:
- build
- test
- codescan
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "mvn clean "
- echo "mvn install"
- echo "$DOMAIN"
after_script:
- echo "after script in buildjob"
unittest:
stage: test
script:
- ech "run test"
when: delayed
start_in: '30'
allow_failure: true
deploy:
stage: deploy
script:
- echo "hello deploy"
- sleep 2;
when: manual
codescan:
stage: codescan
script:
- echo "codescan"
- sleep 5;
when: on_success
after_script:
- echo "after-script"
- ech
14. retry
配置在失败的情况下重试作业的次数。
当作业失败并配置了retry ,将再次处理该作业,直到达到retry关键字指定的次数。如果retry设置为2,并且作业在第二次运行成功(第一次重试),则不会再次重试. retry值必须是一个正整数,等于或大于0,但小于或等于2(最多两次重试,总共运行3次).
unittest:
stage: test
retry: 2
script:
- ech "run test"
默认情况下,将在所有失败情况下重试作业。为了更好地控制retry哪些失败,可以是具有以下键的哈希值:
max:最大重试次数.when:重试失败的原因.
根据错误原因设置重试的次数。
always :在发生任何故障时重试(默认).
unknown_failure :当失败原因未知时。
script_failure :脚本失败时重试。
api_failure :API失败重试。
stuck_or_timeout_failure :作业卡住或超时时。
runner_system_failure :运行系统发生故障。
missing_dependency_failure: 如果依赖丢失。
runner_unsupported :Runner不受支持。
stale_schedule :无法执行延迟的作业。
job_execution_timeout :脚本超出了为作业设置的最大执行时间。
archived_failure :作业已存档且无法运行。
unmet_prerequisites :作业未能完成先决条件任务。
scheduler_failure :调度程序未能将作业分配给运行scheduler_failure。
data_integrity_failure :检测到结构完整性问题。
比如:
当出现脚本错误重试两次,也就是会运行三次。
unittest:
stage: test
tags:
- build
only:
- master
script:
- ech "run test"
retry:
max: 2
when:
- script_failure
15. timeout 超时
特定作业配置超时,作业级别的超时可以超过项目级别的超时,但不能超过Runner特定的超时。
build:
script: build.sh
timeout: 3 hours 30 minutes
test:
script: rspec
timeout: 3h 30m
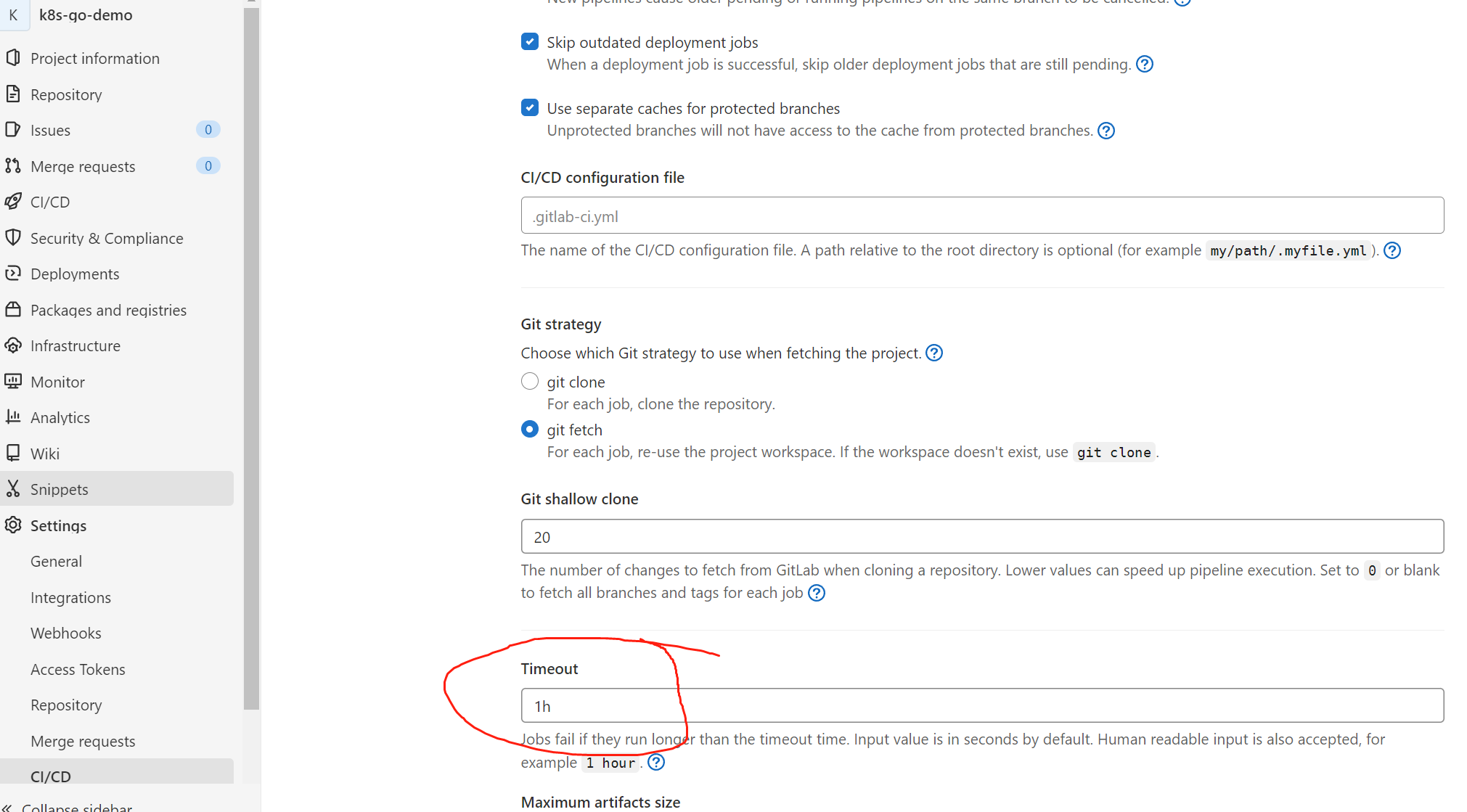
15.1 项目设置流水线超时时间
在项目的设置>CI / CD>常规管道设置下进行配置,默认60分钟
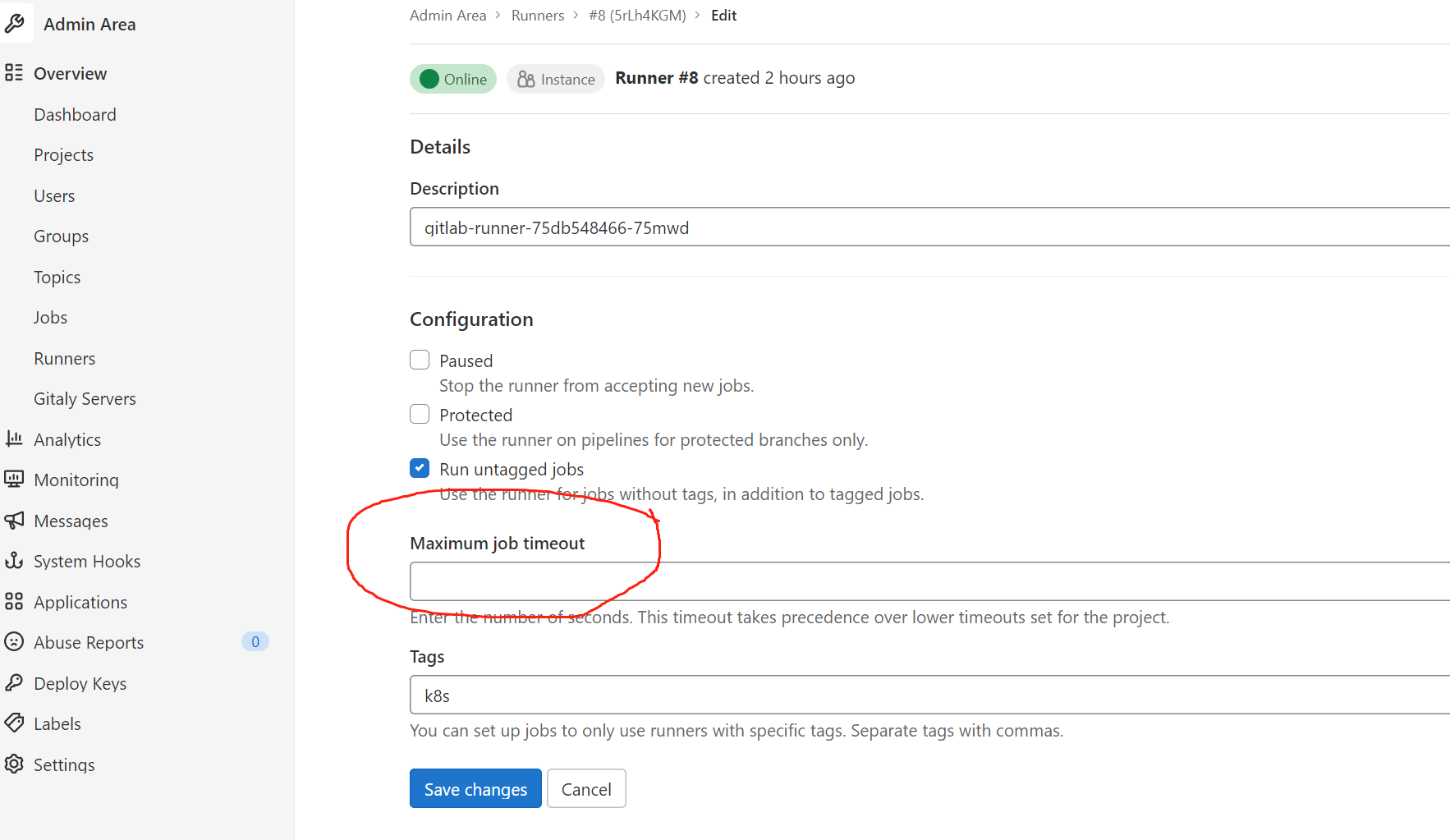
15.2 runner超时时间
此类超时(如果小于项目定义的超时)将具有优先权。
此功能可用于通过设置大超时(例如一个星期)来防止Shared Runner被项目占用。未配置时,Runner将不会覆盖项目超时。
此功能如何工作:
示例1-运行程序超时大于项目超时
runner超时设置为24小时,项目的CI / CD超时设置为2小时。该工作将在2小时后超时。
示例2-未配置运行程序超时
runner不设置超时时间,项目的CI / CD超时设置为2小时。该工作将在2小时后超时。
示例3-运行程序超时小于项目超时
runner超时设置为30分钟,项目的CI / CD超时设置为2小时。工作在30分钟后将超时
16. parallel
配置要并行运行的作业实例数,此值必须大于或等于2并且小于或等于50。
这将创建N个并行运行的同一作业实例. 它们从job_name 1/N到job_name N/N依次命名。
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sleep 5;
parallel: 5
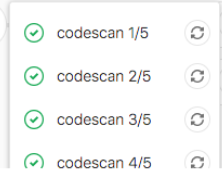
17. 案例3
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
stages:
- build
- test
- codescan
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "mvn clean "
- echo "mvn install"
- echo "$DOMAIN"
after_script:
- echo "after script in buildjob"
unittest:
stage: test
script:
- ech "run test"
when: delayed
start_in: '5'
allow_failure: true
retry:
max: 1
when:
- script_failure
timeout: 1 hours 10 minutes
deploy:
stage: deploy
script:
- echo "hello deploy"
- sleep 2;
when: manual
codescan:
stage: codescan
script:
- echo "codescan"
- sleep 5;
when: on_success
parallel: 5
after_script:
- echo "after-script"
- ech
18. only & except
only和except是两个参数用分支策略来限制jobs构建:
only定义哪些分支和标签的git项目将会被job执行。except定义哪些分支和标签的git项目将不会被job执行。
job:
# use regexp
only:
- /^issue-.*$/
# use special keyword
except:
- branches
19. rules
rules允许按顺序评估单个规则对象的列表,直到一个匹配并为作业动态提供属性. 请注意, rules不能与only/except组合使用。
可用的规则条款包括:
ifchangesexists
19.1 rules:if
如果DOMAIN的值匹配,则需要手动运行。不匹配on_success。 条件判断从上到下,匹配即停止。
多条件匹配可以使用&& ||
variables:
DOMAIN: example.com
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sleep 5;
#parallel: 5
rules:
- if: '$DOMAIN == "example.com"'
when: manual
- when: on_success
19.2 rules:changes
接受文件路径数组。 如果提交中Jenkinsfile文件发生的变化 则为手动。
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sleep 5;
#parallel: 5
rules:
- changes:
- Jenkinsfile
when: manual
- if: '$DOMAIN == "example.com"'
when: on_success
- when: on_success
19.3 rules:exists
接受文件路径数组。当仓库中存在指定的文件时操作。
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sleep 5;
#parallel: 5
rules:
- exists:
- Jenkinsfile
when: manual
- changes:
- Jenkinsfile
when: on_success
- if: '$DOMAIN == "example.com"'
when: on_success
- when: on_success
19.4 rules:allow_failure
使用allow_failure: true,rules:在不停止管道本身的情况下允许作业失败或手动作业等待操作.
job:
script: "echo Hello, Rules!"
rules:
- if: '$CI_MERGE_REQUEST_TARGET_BRANCH_NAME == "master"'
when: manual
allow_failure: true
在此示例中,如果第一个规则匹配,则作业将具有以下when: manual和allow_failure: true。
20. workflow:rules
顶级workflow:关键字适用于整个管道,并将确定是否创建管道。when :可以设置为always或never . 如果未提供,则默认值always。
variables:
DOMAIN: example.com
workflow:
rules:
- if: '$DOMAIN == "example.com"'
- when: always
21. 案例4
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
workflow:
rules:
- if: '$DOMAIN == "example.com"'
when: always
- when: never
stages:
- build
- test
- codescan
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "mvn clean "
- echo "mvn install"
- ech "$DOMAIN"
after_script:
- echo "after script in buildjob"
rules:
- exists:
- Dockerfile
when: on_success
allow_failure: true
- changes:
- Dockerfile
when: manual
- when: on_failure
unittest:
stage: test
script:
- ech "run test"
when: delayed
start_in: '5'
allow_failure: true
retry:
max: 1
when:
- script_failure
timeout: 1 hours 10 minutes
deploy:
stage: deploy
script:
- echo "hello deploy"
- sleep 2;
rules:
- if: '$DOMAIN == "example.com"'
when: manual
- if: '$DOMAIN == "aexample.com"'
when: delayed
start_in: '5'
- when: on_failure
codescan:
stage: codescan
script:
- echo "codescan"
- sleep 5;
when: on_success
parallel: 5
after_script:
- echo "after-script"
- ech
22. cache 缓存
用来指定需要在job之间缓存的文件或目录。只能使用该项目工作空间内的路径。不要使用缓存在阶段之间传递文件,因为缓存旨在存储编译项目所需的运行时依赖项。
如果在job范围之外定义了cache ,则意味着它是全局设置,所有job都将使用该定义。如果未全局定义或未按job定义则禁用该功能。
22.1 cache:paths
使用paths指令选择要缓存的文件或目录,路径是相对于项目目录,不能直接链接到项目目录之外。
$CI_PROJECT_DIR : 项目目录
在job build中定义缓存,将会缓存target目录下的所有.jar文件。
build:
script: test
cache:
paths:
- target/*.jar
当在全局定义了cache:paths会被job中覆盖。以下实例将缓存target目录。
cache:
paths:
- my/files
build:
script: echo "hello"
cache:
key: build
paths:
- target/
由于缓存是在job之间共享的,如果不同的job使用不同的路径就出现了缓存覆盖的问题。如何让不同的job缓存不同的cache呢?
答案是设置不同的cache:key。
22.2 cache:key 缓存标记
为缓存做个标记,可以配置job、分支为key来实现分支、作业特定的缓存。为不同 job 定义了不同的 cache:key 时, 会为每个 job 分配一个独立的 cache。cache:key变量可以使用任何预定义变量,默认default ,从GitLab 9.0开始,默认情况下所有内容都在管道和作业之间共享。
按照分支设置缓存
cache:
key: ${CI_COMMIT_REF_SLUG}
files: 文件发生变化自动重新生成缓存(files最多指定两个文件),提交的时候检查指定的文件。
根据指定的文件生成密钥计算SHA校验和,如果文件未改变值为default。
cache:
key:
files:
- Gemfile.lock
- package.json
paths:
- vendor/ruby
- node_modules
prefix: 允许给定prefix的值与指定文件生成的秘钥组合。
在这里定义了全局的cache,如果文件发生变化则值为 rspec-xxx111111111222222 ,未发生变化为rspec-default。
cache:
key:
files:
- Gemfile.lock
prefix: ${CI_JOB_NAME}
paths:
- vendor/ruby
rspec:
script:
- bundle exec rspec
例如,添加$CI_JOB_NAME prefix将使密钥看起来像: rspec-feef9576d21ee9b6a32e30c5c79d0a0ceb68d1e5 ,并且作业缓存在不同分支之间共享,如果分支更改了Gemfile.lock ,则该分支将为cache:key:files具有新的SHA校验和. 将生成一个新的缓存密钥,并为该密钥创建一个新的缓存. 如果Gemfile.lock未发生变化 ,则将前缀添加default ,因此示例中的键为rspec-default 。
23. cache:policy 策略
默认:在执行开始时下载文件,并在结束时重新上传文件。称为” pull-push缓存策略.
policy: pull 跳过下载步骤
policy: push 跳过上传步骤
stages:
- setup
- test
prepare:
stage: setup
cache:
key: gems
paths:
- vendor/bundle
script:
- bundle install --deployment
rspec:
stage: test
cache:
key: gems
paths:
- vendor/bundle
policy: pull
script:
- bundle exec rspec
24. 案例5
全局缓存生效于未在作业中定义缓存的所有作业,这种情况如果每个作业都对缓存目录做了更改,会出现缓存被覆盖的场景。
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
cache:
paths:
- target/
stages:
- build
- test
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
tags:
- k8s
only:
- master
script:
- ls
- id
- mkdir target
- echo '第一次修改' >> target/a.txt
- ls target
- echo "$DOMAIN"
- sleep 2;
after_script:
- echo "after script in job"
unittest:
stage: test
tags:
- k8s
only:
- master
script:
- echo "run test"
- echo '第二次修改' >> target/b.txt
- ls target
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- k8s
only:
- master
script:
- echo "run deploy"
- ls target
retry:
max: 2
when:
- script_failure
after_script:
- echo "after-script"
上述案例在每次job运行前,都会先下载缓存,如果不想这么做,可以设置
cache:
policy: pull #不下载缓存
比如:
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
cache:
paths:
- target/
stages:
- build
- test
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
tags:
- k8s
only:
- master
script:
- ls
- id
- mkdir target
- echo '第一次修改' >> target/a.txt
- ls target
- echo "$DOMAIN"
- sleep 2;
after_script:
- echo "after script in job"
cache:
policy: pull #不下载缓存
unittest:
stage: test
tags:
- k8s
only:
- master
script:
- echo "run test"
- echo '第二次修改' >> target/b.txt
- ls target
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- k8s
only:
- master
script:
- echo "run deploy"
- ls target
retry:
max: 2
when:
- script_failure
after_script:
- echo "after-script"
这样当第二次运行的时候,就不会出错了。
25. artifacts
用于指定在作业成功或者失败时应附加到作业的文件或目录的列表。作业完成后,artifact将被发送到GitLab,并可在GitLab UI中下载。
25.1 artifacts:paths
路径是相对于项目目录的,不能直接链接到项目目录之外。
将artifacts设置为target目录
artifacts:
paths:
- target/
禁用artifacts传递
job:
stage: build
script: make build
dependencies: []
您可能只想为标记的发行版创建构件,以避免用临时构建构件填充构建服务器存储。仅为标签创建工件( default-job不会创建artifact):
default-job:
script:
- mvn test -U
except:
- tags
release-job:
script:
- mvn package -U
artifacts:
paths:
- target/*.war
only:
- tags
25.2 artifacts:expose_as
关键字expose_as可用于在合并请求 UI中公开作业artifacts:。
例如,要匹配单个文件:
test:
script:
- echo 1
artifacts:
expose_as: 'artifact 1'
paths:
- path/to/file.txt
使用此配置,GitLab将在指向的相关合并请求中添加链接file1.txt。

25.3 artifacts:name
通过name指令定义所创建的artifact存档的名称。可以为每个档案使用唯一的名称。
artifacts:name变量可以使用任何预定义变量。默认名称是artifacts,下载artifacts改为artifacts.zip。
使用当前作业的名称创建档案
job:
artifacts:
name: "$CI_JOB_NAME"
paths:
- binaries/
使用内部分支或标记的名称(仅包括binaries目录)创建档案,
job:
artifacts:
name: "$CI_COMMIT_REF_NAME"
paths:
- binaries/
使用当前作业的名称和当前分支或标记(仅包括binaries目录)创建档案
job:
artifacts:
name: "$CI_JOB_NAME-$CI_COMMIT_REF_NAME"
paths:
- binaries/
要创建一个具有当前阶段名称和分支名称的档案
job:
artifacts:
name: "$CI_JOB_STAGE-$CI_COMMIT_REF_NAME"
paths:
- binaries/
25.4 artifacts:when
用于在作业失败时或者成功时上传工件。
on_success仅在作业成功时上载artifact。这是默认值。
on_failure仅在作业失败时上载artifact。
always 上载artifact,无论作业状态如何。
要仅在作业失败时上传artifact:
job:
artifacts:
when: on_failure
25.5 artifacts:expire_in
artifact的有效期,从上传和存储到GitLab的时间开始算起。如果未定义过期时间,则默认为30天。
expire_in的值以秒为单位的经过时间,除非提供了单位。可解析值的示例:
‘42’
‘3 mins 4 sec’
‘2 hrs 20 min’
‘2h20min’
‘6 mos 1 day’
‘47 yrs 6 mos and 4d’
‘3 weeks and 2 days’
一周后过期
job:
artifacts:
expire_in: 1 week
25.6 artifacts:reports
用于从作业中收集测试报告,代码质量报告和安全报告. 在GitLab的UI中显示这些报告。
注意:无论作业结果(成功或失败),都将收集测试报告。
artifacts:reports:junit
收集junit单元测试报告,收集的JUnit报告将作为artifact上传到GitLab,并将自动显示在合并请求中。
build:
stage: build
tags:
- build
only:
- master
script:
- mvn test
- mvn cobertura:cobertura
- ls target
artifacts:
name: "$CI_JOB_NAME-$CI_COMMIT_REF_NAME"
when: on_success
expose_as: 'artifact 1'
paths:
- target/*.jar
reports:
junit: target/surefire-reports/TEST-*.xml
注意:如果您使用的JUnit工具导出到多个XML文件,则可以在一个作业中指定多个测试报告路径,它们将被自动串联到一个文件中. 使用文件名模式( junit: rspec-*.xml ),文件名数组( junit: [rspec-1.xml, rspec-2.xml, rspec-3.xml] )或其组合( junit: [rspec.xml, test-results/TEST-*.xml] )。
参考:https://docs.gitlab.com/ee/ci/testing/unit_test_reports.html
artifacts:reports:cobertura
收集的Cobertura覆盖率报告将作为工件上传到GitLab,并在合并请求中自动显示。
build:
stage: build
tags:
- build
only:
- master
script:
- mvn test
- mvn cobertura:cobertura
- ls target
artifacts:
name: "$CI_JOB_NAME-$CI_COMMIT_REF_NAME"
when: on_success
expose_as: 'artifact 1'
paths:
- target/*.jar
reports:
junit: target/surefire-reports/TEST-*.xml
cobertura: target/site/cobertura/coverage.xml
比如使用的maven
<plugins>
<!-- cobertura plugin start -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>cobertura-maven-plugin</artifactId>
<version>2.7</version>
<configuration>
<formats>
<format>html</format>
<format>xml</format>
</formats>
</configuration>
</plugin>
<!-- cobertura plugin end -->
</plugins>
执行 mvn cobertura:cobertura 运行测试并产生 Cobertura 覆盖率报告。
参考:https://archives.docs.gitlab.com/15.2/ee/ci/testing/test_coverage_visualization.html
26. dependencies
定义要获取artifacts的作业列表,只能从当前阶段之前执行的阶段定义作业。定义一个空数组将跳过下载该作业的任何artifacts不会考虑先前作业的状态,因此,如果它失败或是未运行的手动作业,则不会发生错误。
如果设置为依赖项的作业的工件已过期或删除,那么依赖项作业将失败。
27. 案例6
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
cache:
paths:
- target/
stages:
- build
- test
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
tags:
- build
only:
- master
script:
- ls
- id
- mvn test
- mvn cobertura:cobertura
- ls target
- echo "$DOMAIN"
- false && true ; exit_code=$?
- if [ $exit_code -ne 0 ]; then echo "Previous command failed"; fi;
- sleep 2;
after_script:
- echo "after script in job"
artifacts:
name: "$CI_JOB_NAME-$CI_COMMIT_REF_NAME"
when: on_success
#expose_as: 'artifact 1'
paths:
- target/*.jar
#- target/surefire-reports/TEST*.xml
reports:
junit: target/surefire-reports/TEST-*.xml
cobertura: target/site/cobertura/coverage.xml
unittest:
dependencies:
- build
stage: test
tags:
- build
only:
- master
script:
- echo "run test"
- echo 'test' >> target/a.txt
- ls target
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- build
only:
- master
script:
- echo "run deploy"
- ls target
retry:
max: 2
when:
- script_failure
after_script:
- echo "after-script"
28. needs
可无序执行作业,无需按照阶段顺序运行某些作业,可以让多个阶段同时运行。
stages:
- build
- test
- deploy
module-a-build:
stage: build
script:
- echo "hello3a"
- sleep 10
module-b-build:
stage: build
script:
- echo "hello3b"
- sleep 10
module-a-test:
stage: test
script:
- echo "hello3a"
- sleep 10
needs: ["module-a-build"]
module-b-test:
stage: test
script:
- echo "hello3b"
- sleep 10
needs: ["module-b-build"]
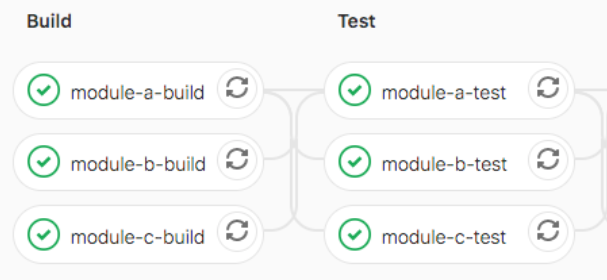
如果needs:设置为指向因only/except规则而未实例化的作业,或者不存在,则创建管道时会出现YAML错误。
限制needs最大的作业分配:ci_dag_limit_needs
默认启用,10个,如果禁用 则为50个。
29. artifacts下载
使用needs,可通过artifacts: true或artifacts: false来控制工件下载。 默认不指定为true。
module-a-test:
stage: test
script:
- echo "hello3a"
- sleep 10
needs:
- job: "module-a-build"
artifacts: true
相同项目中的管道artifacts下载,通过将project关键字设置为当前项目的名称,并指定引用,可以使用needs从当前项目的不同管道中下载artifacts。
在下面的示例中,build_job将使用other-ref下载最新成功的build-1作业的artifacts:
build_job:
stage: build
script:
- ls -lhR
needs:
- project: group/same-project-name
job: build-1
ref: other-ref
artifacts: true
不支持从parallel:运行的作业中下载artifacts。
30. include
可以允许引入外部YAML文件,文件具有扩展名.yml或.yaml 。使用合并功能可以自定义和覆盖包含本地定义的CI / CD配置。相同的job会合并,参数值以源文件为准。
30.1 local
引入同一存储库中的文件,使用相对于根目录的完整路径进行引用,与配置文件在同一分支上使用。
ci/localci.yml: 定义一个作业用于发布。
stages:
- deploy
deployjob:
stage: deploy
script:
- echo 'deploy'
.gitlab-ci.yml 引入本地的CI文件ci/localci.yml。
include:
local: 'ci/localci.yml'
stages:
- build
- test
- deploy
buildjob:
stage: build
script: ls
testjob:
stage: test
script: ls

30.2 template
只能使用官方提供的模板 https://gitlab.com/gitlab-org/gitlab/tree/master/lib/gitlab/ci/templates
include:
- template: Auto-DevOps.gitlab-ci.yml
30.3 remote
用于通过HTTP / HTTPS包含来自其他位置的文件,并使用完整URL进行引用. 远程文件必须可以通过简单的GET请求公开访问,因为不支持远程URL中的身份验证架构。
include:
- remote: 'https://gitlab.com/awesome-project/raw/master/.gitlab-ci-template.yml'
31. extends
继承模板作业
stages:
- test
variables:
RSPEC: 'test'
.tests:
script: echo "mvn test"
stage: test
only:
refs:
- branches
testjob:
extends: .tests
script: echo "mvn clean test"
only:
variables:
- $RSPEC
合并后
testjob:
stage: test
script: echo "mvn clean test"
only:
variables:
- $RSPEC
refs:
- branches
32. extends & include
aa.yml
#stages:
# - deploy
deployjob:
stage: deploy
script:
- echo 'deploy'
only:
- master
.template:
stage: build
script:
- echo "build"
only:
- master
include:
local: 'ci/aa.yml'
stages:
- test
- build
- deploy
variables:
RSPEC: 'test'
.tests:
script: echo "mvn test"
stage: test
only:
refs:
- branches
testjob:
extends: .tests
script: echo "mvn clean test"
only:
variables:
- $RSPEC
newbuildjob:
script:
- echo "123"
extends: .template
33. trigger 管道触发
当GitLab从trigger定义创建的作业启动时,将创建一个下游管道。允许创建多项目管道和子管道。将trigger与when:manual一起使用会导致错误。
多项目管道: 跨多个项目设置流水线,以便一个项目中的管道可以触发另一个项目中的管道。比如微服务架构
父子管道: 在同一项目中管道可以触发一组同时运行的子管道,子管道仍然按照阶段顺序执行其每个作业,但是可以自由地继续执行各个阶段,而不必等待父管道中无关的作业完成。
33.1 多项目管道
当前面阶段运行完成后,触发demo/demo-java-service项目master流水线。创建上游管道的用户需要具有对下游项目的访问权限。如果发现下游项目用户没有访问权限以在其中创建管道,则staging作业将被标记为失败。
staging:
variables:
ENVIRONMENT: staging
stage: deploy
trigger:
project: demo/demo-java-service
branch: master
strategy: depend
project关键字,用于指定下游项目的完整路径。该branch关键字指定由指定的项目分支的名称。使用variables关键字将变量传递到下游管道。 全局变量也会传递给下游项目。上游管道优先于下游管道。如果在上游和下游项目中定义了两个具有相同名称的变量,则在上游项目中定义的变量将优先。默认情况下,一旦创建下游管道,trigger作业就会以success状态完成。strategy: depend将自身状态从触发的管道合并到源作业。
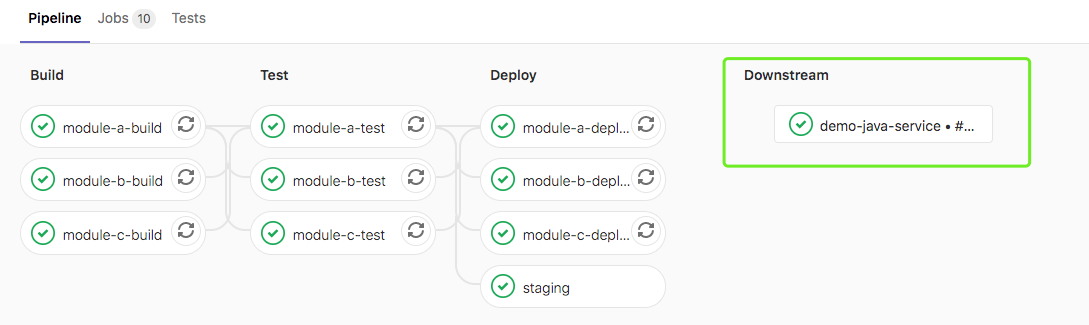
在下游项目中查看管道信息

在此示例中,一旦创建了下游管道,该staging将被标记为成功。
33.2 父子管道
创建子管道ci/child01.yml
stages:
- build
child-a-build:
stage: build
script:
- echo "hello3a"
- sleep 10
在父管道触发子管道
staging2:
variables:
ENVIRONMENT: staging
stage: deploy
trigger:
include: ci/child01.yml
strategy: depend
34. image
默认在注册runner的时候需要填写一个基础的镜像,请记住一点只要使用执行器为docker类型的runner所有的操作运行都会在容器中运行。 如果全局指定了images则所有作业使用此image创建容器并在其中运行。 全局未指定image,再次查看job中是否有指定,如果有此job按照指定镜像创建容器并运行,没有则使用注册runner时指定的默认镜像。
before_script:
- ls
build:
image: maven:3.6.3-jdk-8
stage: build
tags:
- newdocker
script:
- ls
- sleep 2
- echo "mvn clean "
- sleep 10
deploy:
stage: deploy
tags:
- newdocker
script:
- echo "deploy"
35. services
工作期间运行的另一个Docker映像,并link到image关键字定义的Docker映像。这样,您就可以在构建期间访问服务映像.
服务映像可以运行任何应用程序,但是最常见的用例是运行数据库容器,例如mysql 。与每次安装项目时都安装mysql相比,使用现有映像并将其作为附加容器运行更容易,更快捷。
services:
- name: mysql:latest
alias: mysql-1
36. environment
deploy to production:
stage: deploy
script: git push production HEAD:master
environment:
name: production
url: https://prod.example.com
37. inherit
使用或禁用全局定义的环境变量(variables)或默认值(default)。
使用true、false决定是否使用,默认为true
inherit:
default: false
variables: false
继承其中的一部分变量或默认值使用list
inherit:
default:
- parameter1
- parameter2
variables:
- VARIABLE1
- VARIABLE2